

日本語形態素解析システム JUMAN++ Ver.1.02をWindowsでビルドしました。
本稿は、その簡単な紹介と、ソースの修正点を記します。
はじめに
今まで時間をかけてJUMANをWindows用にビルドしPythonモジュールにしました。
次は「日本語形態素解析システムJUMAN++」のWindows環境に挑戦です。(Windows版の公式リリースは2017年10月22日時点でまだありません。)
尚、私の環境は「Windows10 64bit HOME ビルド15063」です。
結果
JUMAN++ Ver.1.02をWindowsでビルドし、動作させることができました。(64bit限定)
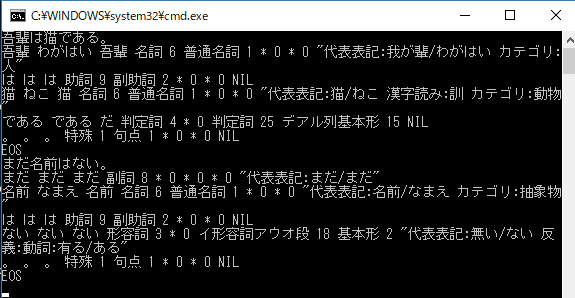
詳しい説明はこちら、ダウンロードはこちらです。(zipの展開後、dics/make_rs.batの実行をお忘れなく)
エクスプローラーから同梱のjumanpp-i.batをダブルクリックすると起動すると、上のように入力を解析します。
またコマンドプロンプトやPower Shellからも、jumanpp-i.bat経由でオプション指定できます。(jumanpp.exeに--encodingオプションつけてもいいのですが。)
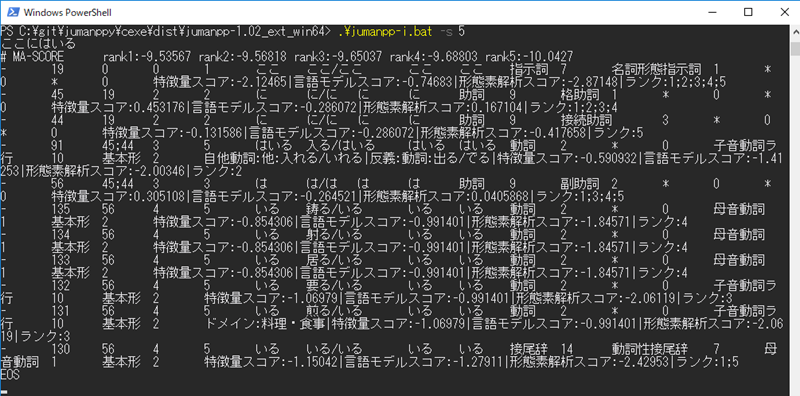
「-s 5」を指定して詳細表示しました。
主な変更点
主な変更点は以下です。
- 文字コードの変換と、ファイルへの入出力の機能追加。(ソースの追加、std::coutを*(param->p_out)に変更等)
- LinuxとWindowsでの、long型のサイズの違いに起因する不具合の吸収。(unsind longをuint64_tに変更、strtoulを_strtoui64に呼び変え等)
- boostライブラリのmanaged_mapped_file::shrink_to_fitの中で例外が発生する問題の吸収。(pos.h, rnnlmlib_dynamic.cpp, feature_vector.hにてshrink_to_fitの前にインスタンスのdelete、或はデストラクタでshrink_to_fit、及び例外の可視化)
- .mapファイルの初期サイズを小さくする。(pos.cc, rnnlmlib_dynamic.cpp, feature_vector.cc。作成関数が.hにあった場合は.ccに移動)
- 辞書・リソースディレクトリ(dict-build, jumanpp-resource)のMakefileを修正/作成。
以下、修正に関してつらつら記したいと思います。
文字コードの変換
目標はスタンドアローンのPythonモジュールなのでなくてもいいかな、と思っていました。
しかし、Windowsで動かすからには、コマンドプロンプトで動かないとインパクトがない!
ということで、JUMANのときに作ったものをC++にリライトして入れました。
先の画面キャプチャのためだけに。
テストはShift_JISしかしていません。UTF-16には対応していません。EUC-JPはたぶん大丈夫です。
一応必要ないときには、無駄なバッファ転送などしないようにしています。
(興味のない方はそろそろ離脱…)
LinuxとWindowsでのlong型のサイズの違い
long型は、64bitのLinuxでは64bit、Windowsでは32bitです。(参照)
オリジナルのJUMAN++に入っている辞書やモデルのうちバイナリのものは、64bit のLinuxで作られているようです。これららを読み込んだり、またその後正常に処理するためには、Windowsでも64bitのデータは64bitとして扱わなければなりません。
そこで、辞書やモデルに関連する部分でのunsigned longをuint64_tに変更しました。(もしかしたら修正洩れがあり、オリジナルのように解析できていない可能性もあります。)
またstrtoulを_strtoui64に呼び変えました。(ここは辞書のキー値になるので結構キモ)
ソースの中ではsize_tも暗黙に64bitとして書いているところもあるようです。しかしこれらは修正していませんので、32bit版でビルドしても正常動作はしません。(すべてのsize_tを検討するのは大変なので、32bit対応はしないつもりです。)
boost C++ライブラリ
boost C++ライブラリ(以降、boost)は大きく、ビルドにもしばらくかかります。
jumanpp(JUMAN++のソースの意味)が参照するのは、boostの一部ヘッダファイルのみで、ライブラリのリンクはしていません。
ですので、もうjumanppが参照しているヘッダファイルのあるディレクトリだけをざっくり持ってきて、コンパクトにしています。(zipでリポジトリに同梱)
ビルドした時にできる.deps内を見れば、もっと小さくはできると思いますが。
boost C++ライブラリ内での例外発生
pos.hのリソースのマップを作っている箇所、managed_mapped_file::shrink_to_fit(boostライブラリのスタティックメソッド) を呼んでいる先で、boostが例外を投げて終了していました。(大元はWindowsAPIのエラー)
ファイルを開いているせいだとアタリをつけて、その前でインスタンスを一旦deleteするようにしました。
同じ問題はrnnlmlib_dynamic.cpp、feature_vector.hでも起きました。後者では、途中でdeleteするのはうまくありませんので、デストラクタでshrink_to_fitするようにしました。
これはWindows固有の問題でしょうか?もしかしたらファイルポインタを巻き戻すだけでよいのかもしれませんが。
.mapファイルの初期サイズを小さくする。
前節のデバッグ中に、.mapファイルの初期サイズを経験的に小さくしました。
.mapの初期サイズが1GBだとディスクを圧迫しますし、初期化(0クリア)にも時間がかかるためです。(再定義時にコンパイルが走りすぎるのも時間がかかるので、作成関数は.ccに移動しました。)
また将来、辞書やモデルのファイルが変わったときに、マップファイルの作成中にboostの例外が発生したら、原因はココ。(自分でハマりそうなので強調。)
boostの投げる例外は捕まえてメッセージを表示するようにはしましたが、そのメッセージを読んでもよくわかりません。orz
辞書・リソースディレクトリのMakefileを修正/作成
デバッグ中に、本体のビルドとリソースのビルドを分けたくて作成しました。
リリースするパケージには、マップや展開された辞書(dic.*)は含めず、大元の辞書ファイル(juman.mdic)を同梱してユーザーサイドで展開するようにしています。zipを小さくするために。
このjuman.mdicは辞書ディレクトリのmakeで作成されます。辞書ファイルは再作成してもversionに書かれたタイムスタンプは更新されないようにしています。オリジナルのversionとは精密に一致はしませんが。
まとめ
Windows 64bitでJUMANPP++を動作させることができました。
御本家はこちらのリポジトリでバージョン2の作業をされているようです。(オープンソースで公開されていることを感謝いたします。)
私は私でWindowsのお気楽AI環境を目指して(余計に苦労して)→To Be Continued